随着大数据技术的发展,实时数据处理已成为现代企业数据处理架构的重要组成部分。Apache Kafka和Apache Flume作为两款主流的开源数据处理工具,在实时数据流处理中发挥着关键作用。它们各自具有独特优势,并能够通过集成实现更高效的数据处理流程。
一、Apache Kafka的核心特性
Apache Kafka是一个分布式流处理平台,专为高吞吐量、低延迟的实时数据流设计。它基于发布-订阅模式,能够处理海量数据流,并确保数据的可靠传输。Kafka的主要特性包括:
- 高吞吐量:支持每秒数百万条消息的处理。
- 持久化存储:数据可持久化到磁盘,避免数据丢失。
- 分布式架构:支持水平扩展,适合大规模数据处理。
- 容错性:通过副本机制保证数据的高可用性。
Kafka常用于日志聚合、事件源处理和实时流处理等场景。例如,在电商平台中,Kafka可用于实时收集用户行为数据,并传输给下游分析系统。
二、Apache Flume的核心功能
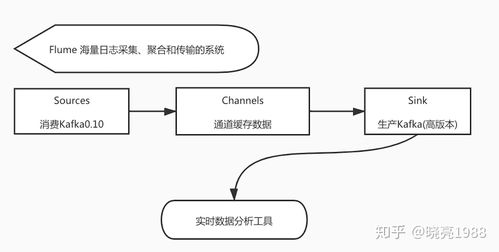
Apache Flume是一个分布式、可靠的日志收集系统,专注于数据采集和传输。它适用于从多种数据源(如日志文件、社交媒体流)收集数据,并将其传输到存储系统(如HDFS、HBase)。Flume的核心组件包括:
- Source:数据源,负责接收数据。
- Channel:数据通道,作为缓冲区,保证数据传输的可靠性。
- Sink:数据目的地,将数据传输到目标系统。
Flume的优势在于其灵活的数据源支持和可靠的数据传输机制。例如,在日志监控系统中,Flume可用于实时收集服务器日志,并将其导入HDFS进行长期存储和分析。
三、Kafka与Flume的集成应用
虽然Kafka和Flume在功能上有重叠,但它们在实际应用中常被结合使用,以发挥各自优势。典型的集成模式包括:
- Flume作为数据采集层,从多种数据源收集数据,并通过Kafka Sink将数据发送到Kafka集群。
- Kafka作为数据缓冲层,接收Flume传输的数据,并提供高吞吐量的数据流处理。
- 下游系统(如Spark Streaming或Flink)从Kafka消费数据,进行实时分析和处理。
这种集成架构的优势在于:
- 灵活性:Flume支持多种数据源,而Kafka提供统一的数据流平台。
- 可靠性:通过Flume的Channel和Kafka的副本机制,确保数据不丢失。
- 扩展性:两者均支持分布式部署,适合处理大规模数据。
四、实时数据处理的最佳实践
在实际应用中,构建高效的实时数据处理流程需注意以下几点:
- 数据格式标准化:确保数据在Flume、Kafka和下游系统间采用一致的格式(如Avro、JSON)。
- 监控与告警:部署监控工具(如Prometheus)来跟踪数据流性能,并及时发现异常。
- 资源规划:根据数据量预估Kafka集群和Flume代理的资源配置,避免瓶颈。
- 安全性:通过SSL/TLS加密数据传输,并实施访问控制策略。
五、总结
Apache Kafka和Apache Flume是实时数据处理生态中的关键组件。Kafka擅长高吞吐量的数据流处理,而Flume专注于灵活的数据采集。通过将它们集成,企业可以构建可靠、可扩展的实时数据处理管道,满足日志分析、事件监控和流式计算等多种需求。随着技术的演进,Kafka和Flume将继续在实时数据领域发挥重要作用,助力企业实现数据驱动的决策与创新。